
node学习笔记(26) - MongoDB(1) :MongoDB初识
MongoDB初识
官方网站 [安装](Install MongoDB Community Edition — MongoDB Manual)
mongodb是一个基于文档的强大、灵活、易于扩展的通用型数据库。是基于分布式文件存储的数据库。其由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。它是一种非关系型数据库,这也就意味着它不像mysql这些关系型数据库一样有着外键约束(一个表中的键值可以关联另一张表)等功能, 更加的自由高效
特点:
- 数据文件存储格式为
BSON(JSON的扩展,可以认为是二进制的json)。{“name”:“joe”}这是BSON的例子,其中"name"是键,"joe"是值。键值对组成了BSON格式。 - 面向集合存储,易于存储对象类型和
JSON形式的数据。所谓集合(collection)有点类似一张表格,区别在于集合没有固定的表头。 - 模式自由。一个集合中可以存储一个键值对的文档,也可以存储多个键值对的文档,还可以存储键不一样的文档,而且在生产环境下可以轻松增减字段而不影响现有程序的运行。
- 支持动态查询。
mongodb支持丰富的查询表达式,查询语句使用JSON形式作为参数,可以很方便地查询内嵌文档和对象数组。 - 完整的索引支持。文档内嵌对象和数组都可以创建索引。
- 支持复制和故障恢复。
mongodb数据库从节点可以复制主节点的数据,主节点所有对数据的操作都会同步到从节点,从节点的数据和主节点的数据是完全一样的,以作备份。当主节点发生故障之后,从节点可以升级为主节点,也可以通过从节点对故障的主节点进行数据恢复。 - 二进制数据存储。
mongodb使用传统高效的二进制数据存储方式,可以将图片文件甚至视频转换成二进制的数据存储到数据库中。 - 自动分片。自动分片功能支持水平的数据库集群,可动态添加机器。分片的功能实现海量数据的分布式存
- 支持多种语言。支持
C++、 C#、 Erlang、Haskell、JavaScript、Java、Perl、PHP、Python、Ruby、Scala等开发语言。 mongodb使用的是内存映射存储引擎。mongodb会把磁盘IO操作转换成内存操作,如果是读操作,内存中的数据起到缓存的作用;如果是写操作,内存还可以把随机的写操作转换成顺序的写操作,总之可以大幅度提升性能。这也是mongodb快的原因。坏处是没有办法很方便地控制mongodb占多大内存,mongodb会占用所有能用的内存,所以最好不要把别的服务和mongodb放在同一台服务器部署。- 这里再提示一下,批量数据处理中,数据库的读写吞吐量与实时性大概是负相关的。
这里注意一下与redis的区别。redis存储的是键值对,本身没有办法分析数据;mongodb相当于一个大数组,本身提供了一些处理功能,如后面提到的聚合。很多复杂的查询只能通过聚合实现,这样的话redis就做不了了。
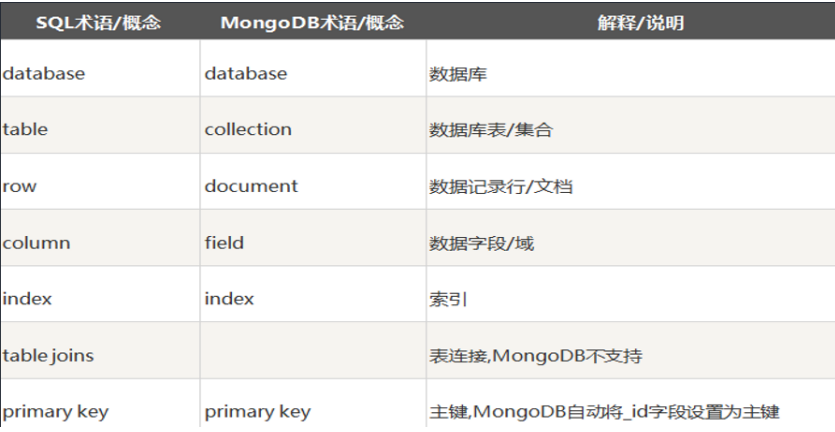
关系型数据库和非关系型数据库的对比


安装与启动:
- 安装(这里使用的是免安装版本)
获取连接 提取码: 30s4
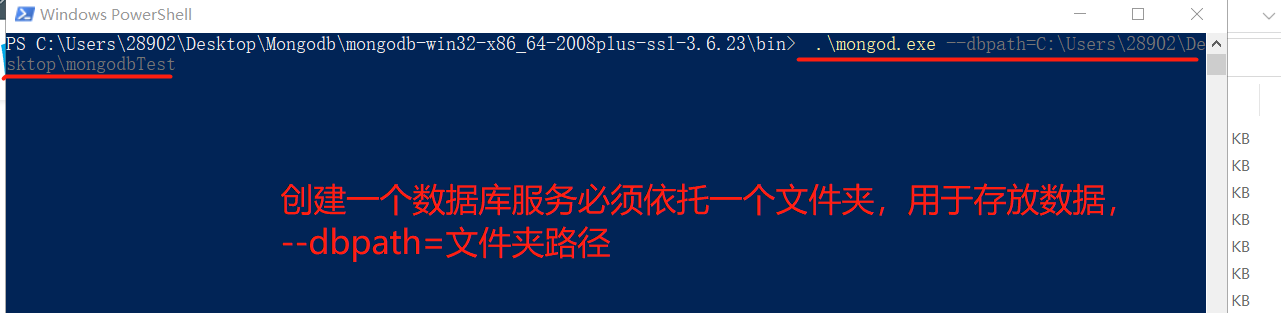
- 启动
# 启动数据库服务端(指定数据保存文件夹) |
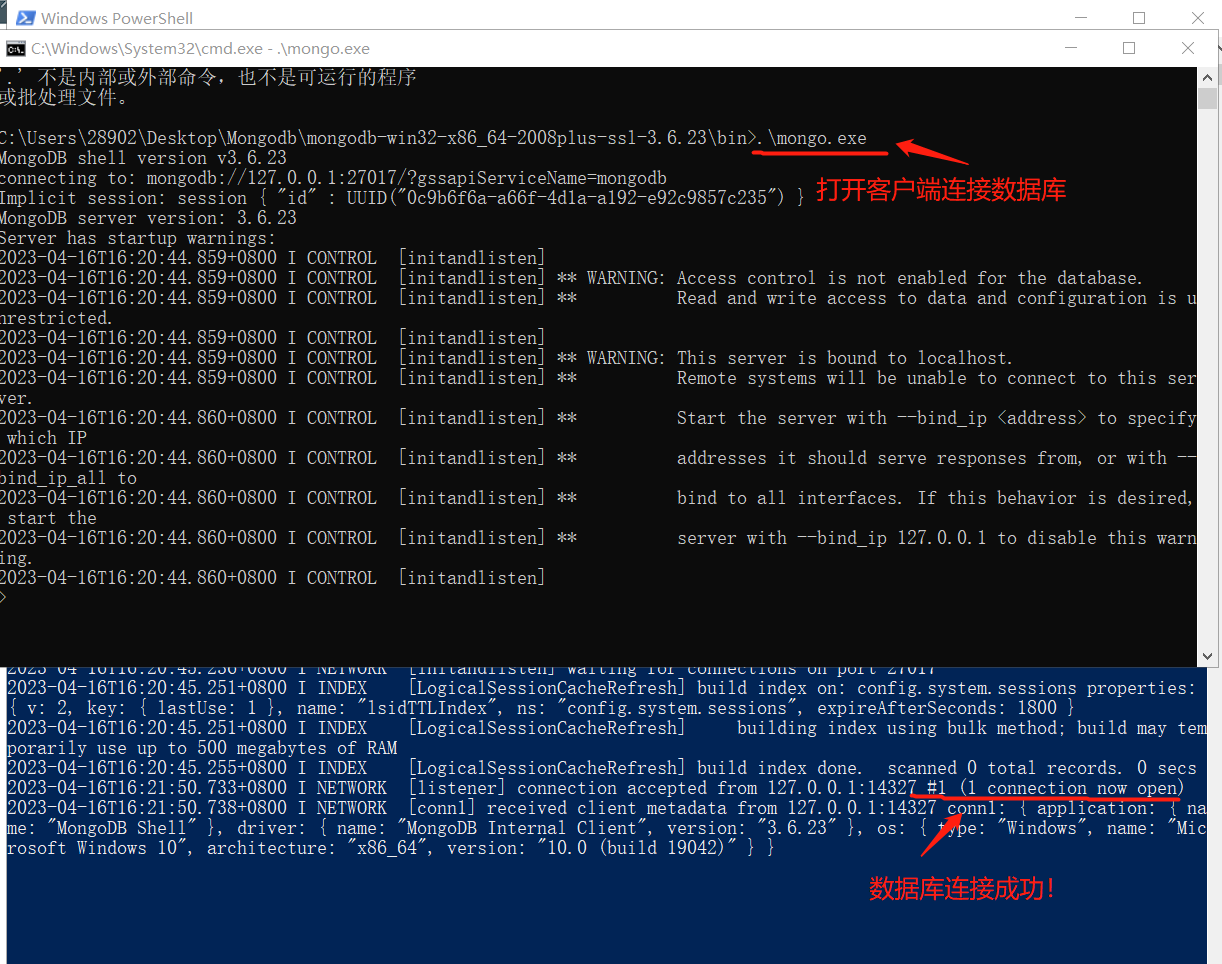
命令行操作
1. 查看常用的指令(help), 查看当前数据库名称(db), 查看当前中的数据库(show dbs)
help |
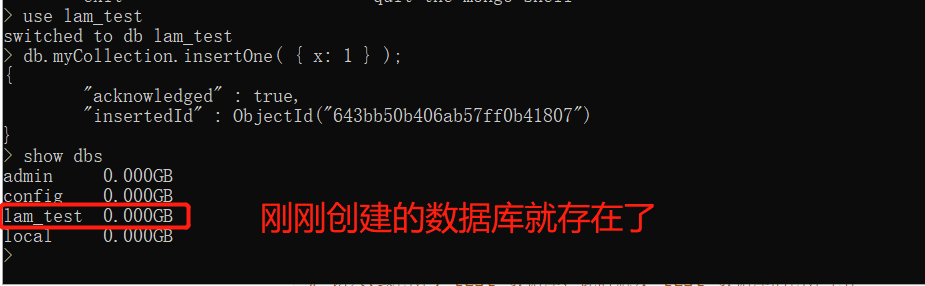
2. 创建数据库
# 切入(或创建) test 数据库,此时触发 test 数据库的创建工作 |
3. 删除数据库
# 删除代码执行前最好是进入该数据库后执行 use <database> |

4. 创建数据库集合(相当于mysql中的创建表)
# 创建的集合名称 选项 |
参数说明:
name: 要创建的集合名称options: (可选)参数的集合
options可以是如下参数:
参数名 类型 描述 capped布尔 (可选)如果为 true,则创建最大容量的集合,如果超出容量capped集合将自动的覆盖旧数据,当设置为true时,则需要指定size参数大小进行设置 autoIndexId布尔 (可选)如为 true,自动在 _id 字段创建索引。默认为 false。【3.4版本开始移除该参数详见[SERVER-19067] Warn at creation that autoIndexId:false is deprecated - MongoDB Jira】 size数值 (可选)为固定集合指定一个最大值,即字节数。
如果 capped 为 true,也需要指定该字段。max数值 (可选)指定固定集合中包含文档的最大数量。
- [注]在插入文档时,
MongoDB首先检查固定集合的size字段,然后检查max字段。
# 例子展示: |
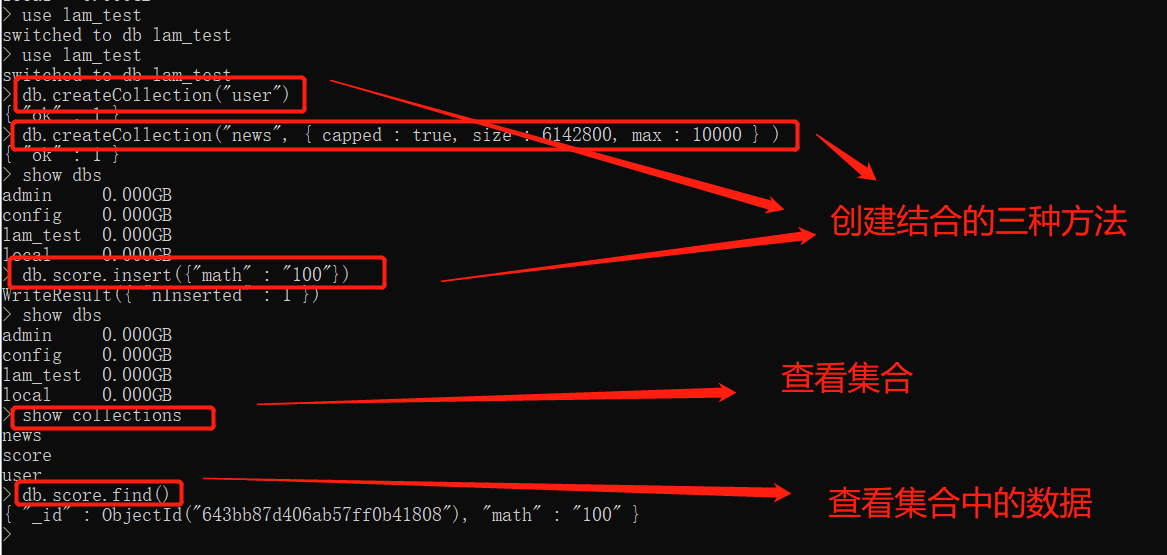
5.操作集合
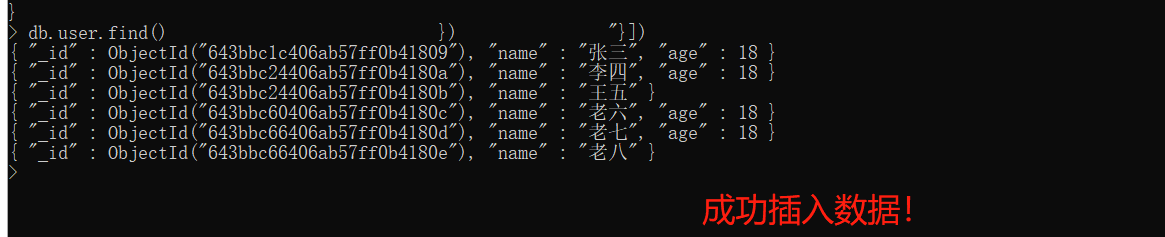
新增数据
# 1. 使用insert(documents)方法 常用,可以单个插入也可以多个插入 |
修改数据
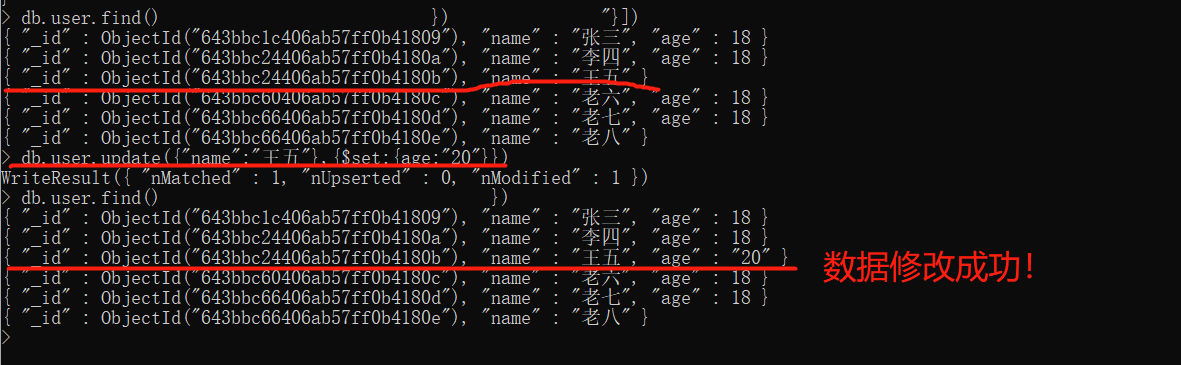
# 1. 使用update方法,切记要结合$set来使用,否则会将你输入的数据完全覆盖掉源数据 |
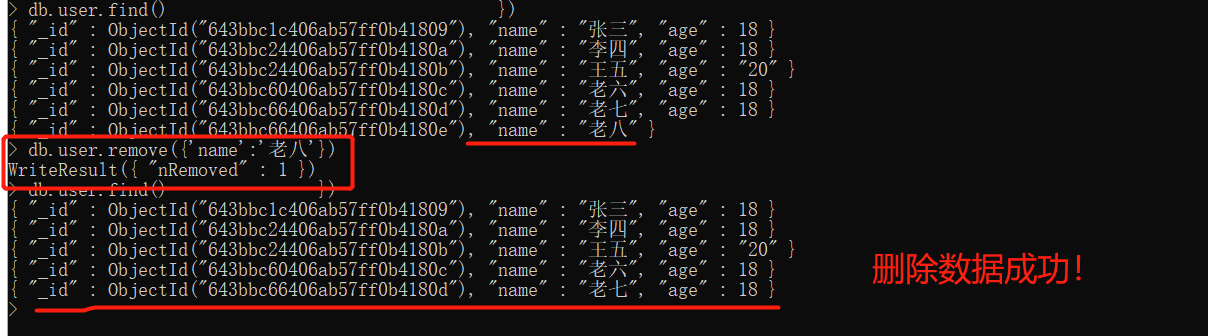
删除数据
db.user.remove({'name':'老八'}) |
查找数据
- 查询过滤器
# 使用查询过滤器从集合中检索文档。查询过滤器是一组键值对,可按字段值查询文档。 |
- 范围查询操作符
# 范围查询操作符可用于构建基于值范围的查询过滤器。 |
- 正则表达式
# 可以使用正则表达式查询字符串字段的值。使用$regex操作符指定正则表达式 |
- 投影操作
# 可以使用投影操作从文档中选择需要的字段。 |
- 排序操作
# 可以使用$sort操作对结果进行排序。 |
- 限制结果数量以及跳过结果数量(分页查询)
# 可以使用$limit操作限制结果数量和$skip操作跳过结果数量 |
- 获取统计数量
db.user.count({"age":18,"name":"张三"}) #统计结果数量,查询name:张三且age为18的数据条数 |
pretty()方法以易读的方式查看查询结果
db.user.find().pretty() |
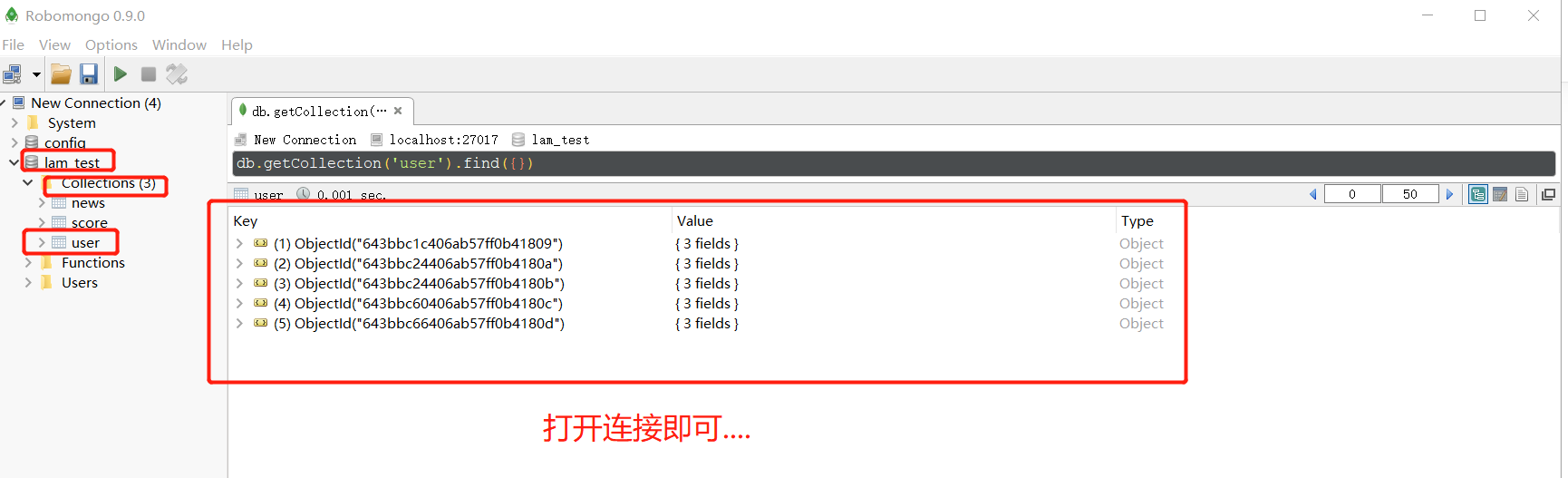
数据可视化操作
- 软件Robomongo获取 提取码: 30s4
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0许可协议。转载请注明来自 肥林の仓库
相关推荐




