
nodejs学习笔记(5)-内置模块(4)-stream模块,zlib模块和path模块
stream模块
stream是Node.js中fs模块提供的又一个仅在服务区端可用的子模块,目的是支持“流”这种数据结构。什么是流?流是一种抽象的数据结构。想象水流,当在水管中流动时,就可以从某个地方(例如自来水厂)源源不断地到达另一个地方(比如你家的洗手池)。我们也可以把数据看成是数据流,比如你敲键盘的时候,就可以把每个字符依次连起来,看成字符流。这个流是从键盘输入到应用程序,实际上它还对应着一个名字:标准输入流(
stdin)。数据流就是数据不是一次性全部返回或者一次性全部读取的,他是通过先读取(或者写入)一部分,再读取(或者写入)一部分,知道最后完成数据的全部操作的,因此
stream模块更加适用于大型数据的读取或者写入操作如果应用程序把字符一个一个输出到显示器上,这也可以看成是一个流,这个流也有名字:标准输出流(
stdout)。流的特点是数据是有序的,而且必须依次读取,或者依次写入,不能像Array那样随机定位。有些流用来读取数据,比如从文件读取数据时,可以打开一个文件流,然后从文件流中不断地读取数据。有些流用来写入数据,比如向文件写入数据时,只需要把数据不断地往文件流中写进去就可以了。
在
Node.js中,流也是一个对象,我们只需要响应流的事件就可以了:data事件表示流的数据已经可以读取了,end事件表示这个流已经到末尾了,没有数据可以读取了,error事件表示出错了。
代码展示:
- 读取数据流(
readStream可读流.js)
// nodejs内置模块:stream(文件流操作) - createReadStream(文件可读流) |
- 写入数据流(
writeStream可写流.js)
// nodejs内置模块:stream(文件流操作) - createWriteStream(文件可写流) |
- 管道连接读写数据流(
pipe管道连接流.js)
// nodejs内置模块:stream(文件流操作) - pipe(文件可写流) |
pipe就像可以把两个水管串成一个更长的水管一样,两个流也可以串起来。一个Readable流和一个Writable流串起来后,所有的数据自动从Readable流进入Writable流,这种操作叫pipe。- 在
Node.js中,Readable流有一个pipe()方法,就是用来干这件事的。 - 让我们用
pipe()把一个文件流和另一个文件流串起来,这样源文件的所有数据就自动写入到目标文件里了,所以,这实际上是一个复制文件的程序
zlib模块
浏览器解析页面的大致流程如下:
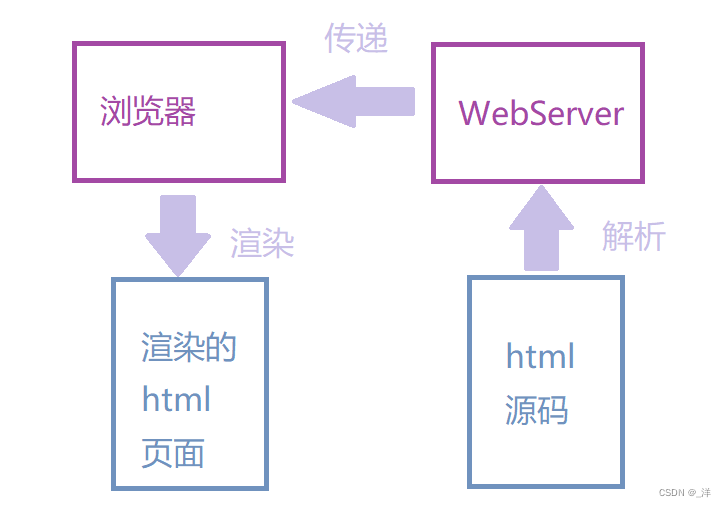
- 由此可见,如果文件过大从
webserver到浏览器的传输时间就会很长所以我们可以先将文件压缩成gzip文件再进行传输。
代码展示:
// nodejs内置模块:zlib(文件压缩) |
结果展示:
使用
zlib压缩前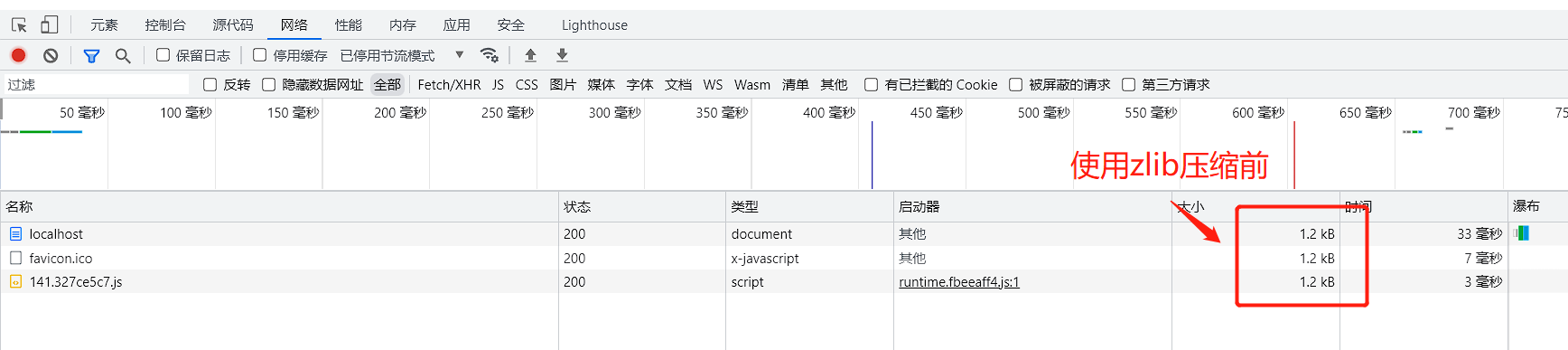
使用
zlib压缩后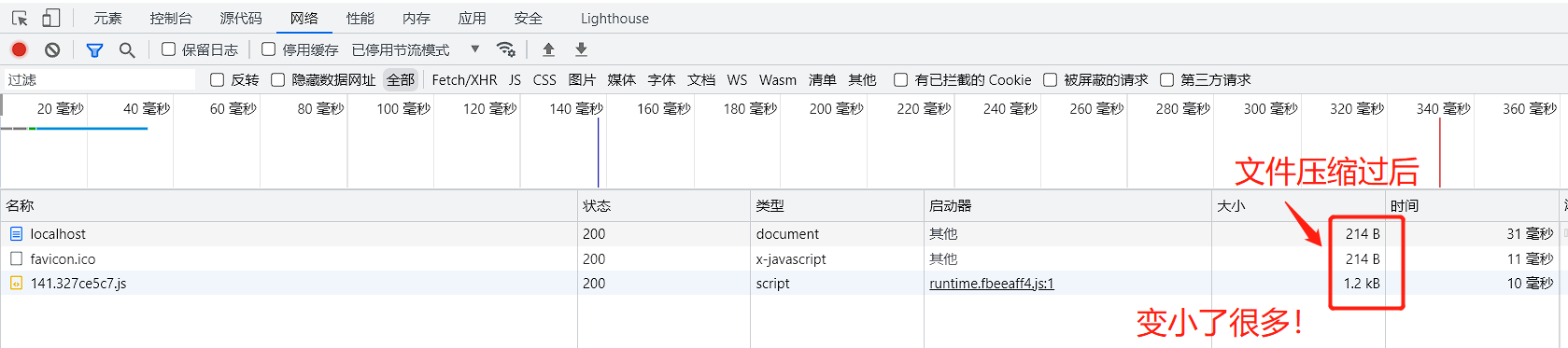
path模块
path模块是Node.js官方提供的、用来处理路径的模块。它提供了一系列的方法和属性,用来满足用户对路径的处理需求。例如:
path.join()方法,用来将多个路径片段拼接成一个完整的路径字符串path.basename()方法,用来从路径字符串中,将文件名解析出来path.extname()方法 获取文件的拓展名,即后缀名
代码展示:
path.join()进行路径的拼接.js
//首先导入相对应的模块 |
结果展示:

path.basename()读取文件名.js
// 使用 path.basename() 方法,可以获取路径中的最后一部分,经常通过这个方法获取路径中的文件名 |
结果展示

path.extname()获取拓展名.js
// path.extname() 只获取文件的拓展名,即后缀名 |
- 结果展示:

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0许可协议。转载请注明来自 肥林の仓库
相关推荐



